About my internship
Ever wondered how your smartphone camera instantly recognizes faces? Or how self-driving cars navigate through traffic? The answer lies in an incredibly powerful aspect of machine learning - Object Detection.
Object detection is all about teaching machines how to identify specific objects within an image or a video. It's a two-part process: first, it finds where an object is (localization), and then identifies what the object is (classification).
- Localization is about pinpointing the position of an object within an image. The algorithm generates a bounding box around the object.
- Classification on the other hand, is about determining what the object is. It might be a cat, a car, or in our case, a traffic sign.
As some of you may know, the main reason I was in Hanoï this summer was to work on a computer science project as my summer internship. The goal was to build a traffic sign detector using YOLO algorithm which is one of the most popular object detector algorithm available. So what's the point of me building an object detection model if one already exists ? YOLO algorithm is trained to recognize objects of any kinds but my goal was to train it to detect specific traffic signs (16 exactly) such as stop, no passing, pedestrians, etc... In this article I will explain my working process in order to build such a model.
Building an object classification model
As I said, object detection consists of 2 parts: localization and classification. Building a localization model is long and complicated, having no experience in machine learning, I decided to first implement my own object classification model. Let's dive deeper into the process.
Classification refers to the task of predicting the class or category of an object. In the context of traffic sign detection, this would mean predicting which type of traffic sign is present in a given image or video frame. This task is accomplished using Convolutional Neural Networks (CNNs). CNNs are a type of artificial neural network designed to process pixel data of images, recognize various patterns in them, and categorize the images based on those patterns. Take a good look at this representation of a CNN because we will often refer to it.
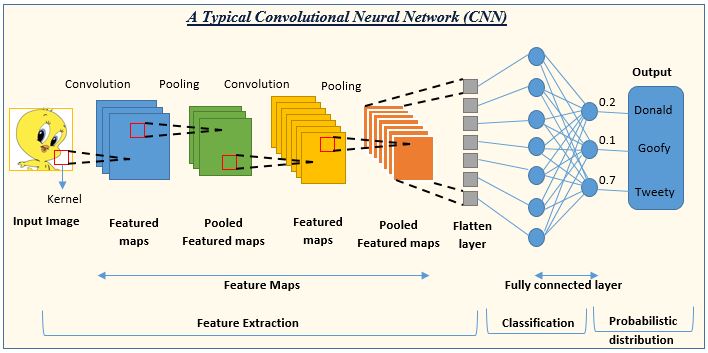
See an image as a list of numbers
As you can see, there are different parts in a CNN. First we have the image. An image can be thought of as a grid, where each cell corresponds to a tiny dot on the image, called a pixel. Each pixel is made up of three numbers, which represent the colors that mix together to create that pixel's color. These three numbers are usually referred to as the Red, Green, and Blue (RGB) values. By combining these RGB values for all the pixels in the image, we get the full picture with its colors and details. So, an image can be represented as a matrix, where each position in the matrix holds the RGB values of a specific pixel. Because each coordinate of the matrix has 3 other coordinates, we call that type of data structure a tensor which is basically a multi-dimensional array. Just like that an image can be seen as a list of digits by the computer. Now that we dispose of our input, let's see what are the different steps of a CNN.
Convolution
In the context of processing an image, a convolution is performed between the image’s pixels and a filter or a kernel. This filter is a small matrix that is used for blurring, sharpening, edge detection, and other image processing functions. The convolution operation involves multiplying the pixel values of the image by the values in the filter, and then summing them up to produce a single number. This process is repeated for every pixel in the image, resulting in a new matrix known as a 'feature map' or 'convolved feature' which is basically our modified image. The feature map represents the area in the input image where certain features are detected by the kernel. For example, a kernel designed to detect edges in an image will produce a feature map that highlights the edges.

Pooling
A pooling layer in a Convolutional Neural Network (CNN) performs a form of downsampling or dimensionality reduction.
How does it work?
- It scans the input image with a kernel that strides across the image spatially (left to right, top to bottom).
- The filter performs a specific operation for that patch of the image. This operation could be finding the maximum value (Max Pooling), average value (Average Pooling), or a more complex operation.
- It produces a condensed version of the image, keeping the most prominent features and discarding the less significant data.
The magic of pooling lies in its ability to provide a form of translation invariance. What does this mean? Well, let's say we're trying to detect a stop sign. The pooling layer doesn't care if the stop sign is at the top left corner, the center, or the bottom right of the image. It's like an eagle-eyed sentinel, picking out the stop sign wherever it might be.
| Type of Pooling | Operation |
|---|---|
| Max Pooling | Selects the maximum value from each patch of the image |
| Average Pooling | Calculates the average value for each patch of the image |

In summary, a pooling layer compresses the image data, accentuates the important features, and provides translation invariance, all while reducing computational cost and the risk of overfitting.
Imagine having a beautiful painting reduced to its essential features - that's what the pooling layer does! It's a clever trick of the trade that helps us get a handle on the immense amount of data we're dealing with when analyzing images. Now, let's dig a little deeper into how we leap from this condensed version of our image, our 'pooled feature map', to the flatten layer.
Flattening the last pooling layer's output
We've got our pooled feature map - a compressed, yet meaningful representation of our image. But how do we interact with this in the neural network? Here's where the magic happens: the flatten layer. This step converts our pooled feature map from a 2D array into a 1D array, or a 'flattened' version, that can be inputted into the next layer of our network.
Think of the flatten layer as the bridge between the world of images and the world of algorithms. It's a translator that helps both sides understand each other better.
- Starting with the pooled feature map, we look at the two-dimensional grid of values that represent the most important features of our image.
- We then 'flatten' this information, transforming it into a one-dimensional array. This is like taking a row of dominoes and lining them up one after the other in a single, straight line.
- This flattened array of values is then ready to be fed into the next step of our machine learning model - the fully connected layer.
Entering the "world of algorithms" - Neural networks
As we said earlier, having a one-dimensional array allow us to enter the world of algorithms because now we can enter what we call the fully connected layers of a CNN.
It's a critical section of our CNN that becomes feasible to implement once our data is in a one-dimensional array structure.

| Role of Fully Connected Layers | Description |
|---|---|
| Integrating Information | They integrate the information derived from preceding layers by taking into account the output from all the neurons. |
| Computing the Output | They compute the output of the network by considering each neuron's outcome and making the final decision. |
| Backpropagation | They play a significant role in backpropagation, a mechanism for learning and improving performance over time. |
I won't explain here fully-connected layers in detail, you can understand how they work there and to have a much deeper understanding about the core math behind them, take a look at this. Let's just say that they allow our model to learn from its mistakes using backpropagation.
Building our model
Now that we have the theory behind CNNs, how do we build a model for this task?
First, we need a database of images containing traffic signs, referred to as a dataset. This dataset needs to be labeled, meaning each image should be marked with the category of traffic sign it contains. This is a crucial part of supervised learning, which is the type of machine learning we are employing here.
Once we have our labeled dataset, we can divide it into two categories: a training set and a validation set. The training set is used to train our model, while the validation set is used to evaluate its performance and prevent overfitting (when overfitting occurs, it implies that our model has essentially learned the training data to an extent where it negatively impacts the model's performance on new, unseen data).
The training process involves passing our images through the CNN, which will then make a prediction for the category of each image. We then compare this prediction with the actual label of the image. The difference between the prediction and the actual label is calculated as an error using a loss/cost function. The aim of the training process is to minimize this loss function, which would mean our model's predictions are becoming more accurate.
To do so, the model's parameters are updated in each iteration of the training process (this is backpropagation) using an optimization algorithm, typically Stochastic Gradient Descent (SGD) or a variant of it.
After doing so, I managed to obtain a 98.5% accuracy which seemed weird to me since my model was really simple. At the time, I didn't fully understand computer vision and thought that was it. Little did I know that this was just the beginning and that object detection models were actually way more complicated. My model was trained on pre-cropped images like this one:

My model's typical training image |

The type of image I wish my model could recognise the traffic signs of |
But when I tried it on images from the street, the results were completly off. That's because it didn't know how to locate objects and this is what we are going to explain in the next part.
Understanding object localization
Object localization is a whole other story. Because I lack time and experience, I used and fine-tuned (form of transfer learning which consists in training a model that has already been trained for some task and then tunes or tweaks the model to make it perform a second similar task) to serve my purpose. This is where the YOLO (You Only Look Once) algorithm comes into play. YOLO is a popular object detection method in computer vision and machine learning. Unlike other object detection methods that output bounding boxes, YOLO uses a single neural network to predict both the bounding boxes and their class probabilities. This makes it extremely fast and efficient, especially for real-time object detection tasks.
The process of building the dataset is crucial to training the machine learning model. The dataset consists of images of the traffic signs and their corresponding labels. The images are then annotated with bounding boxes to indicate the location of the traffic signs. This data is used to train the model to recognize and locate the traffic signs in an image. Once the dataset is built, the next step is to train the YOLO algorithm with this dataset. The training process involves feeding the algorithm with the input images and the corresponding labels. The algorithm then learns to identify the patterns in the images that correspond to the traffic signs. Over time, with enough training, the algorithm becomes proficient at detecting traffic signs, thereby successfully serving as a traffic sign detector. Here are some examples of test batches after training yolov5 on my custom built dataset.

Labeled images, we want our model to predict the same bounding boxes |

Our model's predictions on the same images. As we can see, most guesses are right |
In wrapping up this fascinating exploration into the world of deep learning and object detection, I'd like to underscore the potential of the YOLO algorithm. As we've seen, its application in traffic sign detection is just the tip of the iceberg. It's an exciting era for machine learning and I'm thrilled to be part of it. The best is yet to come!
Comments
Post a Comment